
In the age of big data, almost every business feels the urge to establish its data platform. Presently, there are numerous offline solutions available, including those within the Hadoop ecosystem like CDH and TDH, along with traditional data warehouses. Yet, two substantial hurdles hinder enterprises: the need for “real-time” data and the imperative of “data fusion.”
On one hand, with the constant evolution of IT architecture and the advent of omnichannel marketing on the business front, the demand for real-time data has surged. On the other hand, the legacy of decades of digitalization has resulted in a landscape of data silos and isolated systems. Only when these data islands are fused can they be effectively utilized.
So, what’s the solution for crafting an enterprise-level real-time data fusion platform? TapData has unearthed a promising approach. This article will exemplify the process using one of TapData’s clients in the retail sector as a case study. We’ll demonstrate how to swiftly construct an enterprise-class real-time data fusion platform, harnessing the power of MongoDB.
TapData’s client is a distinguished player in the jewelry retail industry, boasting a rich heritage dating back to the 1990s. With a presence in over 700 retail outlets across mainland China, Hong Kong, Macau, and Taiwan, they offer a diverse product range, including jewelry and related items. Their marketing channels encompass mobile platforms and online marketplaces.
As their business expanded, the need to integrate with multiple e-commerce platforms for product listing and the growing frequency of developing new marketing applications posed challenges to the IT department. Each time they needed to extract data from various databases to initiate iterative development, this resulted in elevated development costs and substantial resource allocation during the data preparation phase.
One typical scenario revolved around inventory auditing in physical stores. When a store clerk made a sale, the sales system recorded the transaction. However, this data represented the current inventory up to that point, and it didn’t necessarily align with the actual store inventory. Errors could occur, such as if a clerk forgot to record a sale, leaving the system showing 1000 items when only 999 were left in stock. These discrepancies, when not audited, went unnoticed by finance and logistics departments, as the system reported 1000 items.
Two fundamental issues arose: the time-consuming nature of manual audits and a high margin for error.
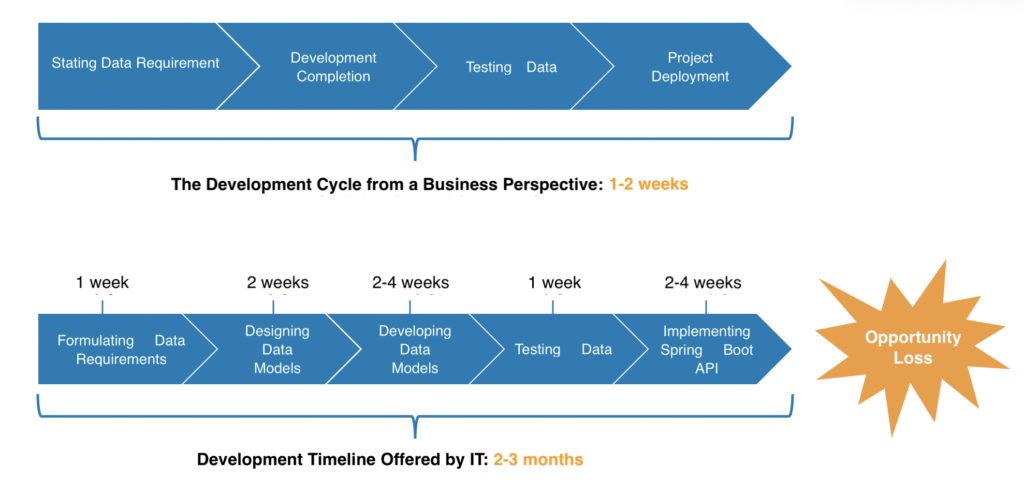
The root cause of these issues lies in the traditional IT development model, where requirements are established, business analysts specify the tasks, data models are defined, and then data development commences. However, from the perspective of the business units, these requirements seemed like mere page creation and report generation tasks that could be completed in a week at most. Consequently, as requirements piled up, IT departments struggled to keep up, leading to significant delays in launching new business systems, ranging from a month to several months.
In turn, business units could not accept these delays. For instance, during major promotional events like “Black Friday“, business units provided requirements three months in advance. However, two weeks before the event, a new policy emerged that didn’t pass the audit due to certain reasons, necessitating a change in the business process. At this point, the development team claimed that adjustments couldn’t be made, resulting in the unfortunate cancellation of the promotion. Missing out on such crucial events like Black Friday could significantly impact the retail industry’s annual performance.
Who bears the responsibility for these issues? A deeper analysis reveals the fundamental problem: data architecture has not kept pace with evolving demands.
Firstly, there are data silos, a common issue in many traditional businesses centered around their core operations. These companies often rely on third-party purchases for their IT systems, and each new system purchase comes with its own set of databases, such as Oracle, MySQL, PostgreSQL, and some newer non-relational databases. While these systems solve their business problems, they pose a headache for their IT departments when new business needs arise on top of these existing systems.
Secondly, there are too many business systems, and they have aged significantly, leading to lower maintainability. For example, some stored procedures consist of thousands of lines of code, with maintenance dating back to 2000. Each stored procedure involves over a dozen maintainers. This historical baggage makes it challenging to effectively iterate and maintain the entire system.
Thirdly, these business systems are typically managed by different business units, some even under the purview of HR. This makes it difficult to access certain business data, negatively affecting the entire development cycle.
Finally, for developers, initiating development once requirements are clear is crucial. Halfway changes in requirements or late feedback that the delivered solution is not what was wanted is a significant challenge.
So, how do we help enterprises effectively address these issues? TapData proposes a solution based on a Data as a Service (DaaS) architecture. This involves creating a real-time data fusion platform and offering several key capabilities:
Real-time synchronization of heterogeneous databases to address real-time query challenges between business systems and downstream systems. This involves unifying data since databases across various regions are often dispersed. A single order might be stored in all databases, but the statuses can be inconsistent. To retrieve the final status, you’d need to query all databases, which is time-consuming.
Using real-time synchronization and data modeling, data is supplied to the search engine database to solve the timeliness problem of full-text search. This facilitates real-time front-end searching on mobile platforms, providing instant results. In traditional retail, common search methods involve extensive SQL queries or fuzzy searches in relational databases, leading to query times of over ten seconds in some systems, significantly decreasing the efficiency of store sales personnel.
Supporting rapid API deployment to create a closed loop for data delivery to downstream business systems. Offering standardized RESTful APIs can significantly reduce development integration costs, while rich GraphQL-like query semantics cater to various business scenario conditions.
In summary, TapData offers a platform that enables real-time querying, full-text searching, and the rapid delivery of unified data, addressing the challenges faced by businesses in today’s dynamic environment.

It’s crucial to highlight the significance of master data management in the retail industry. In retail, the core master data comprises three essential elements: orders, inventory, and products. What sets these master data apart from traditional data warehouses is that the latter typically consist of dimension and fact tables primarily used for reporting. In contrast, these master data are the lifeblood of every project, encompassing areas such as marketing, market activities, and more. This type of data is commonly known as real-time enterprise master data.
In conventional relational database design, a single product table is often associated with dozens of attribute tables. In practical development, a significant portion of time is dedicated to data preparation. Data needs to be procured from various project teams or the core data sources within the enterprise. However, a critical question arises: Who is responsible for data consistency? When individual project teams independently manage their data, it results in a growing number of data links originating from the core database. Each development team may interpret data synchronization business logic differently, leading to a challenge in maintaining data consistency. This is a common issue faced by many enterprises today.
It’s evident that, in terms of development cycles, a substantial amount of time is consumed by data preparation, diverting focus away from core business activities. TapData’s real-time data integration platform streamlines the entire data integration process, significantly reducing the time and human resources required for data preparation. But how does TapData achieve this?
The initial step involves bringing all databases, irrespective of whether they are traditional relational databases like Oracle or MySQL or NoSQL databases, into our platform through real-time synchronization. Our platform leverages two databases: MongoDB and a Search engine database. These databases share strikingly similar data models and are highly complementary across various business scenarios. Here, mongoDB is tasked with rapid data processing and delivery to the front end. We ingest data into MongoDB and proceed to consolidate the data.

For instance, let’s consider the product model. In a relational database, this typically spans across dozens of tables. We can aggregate these tables into a single consolidated view, a comprehensive wide table. This wide table is continually updated in real-time as business transactions occur. For example, if an Enterprise Resource Planning (ERP) or Manufacturing Execution System (MES) processes a new order, the status of that order is instantly updated in the wide table. Subsequently, the product’s master data in MongoDB is pushed to the search engine database.

On the front end, we are no longer restricted to traditional Business Intelligence (BI) tools such as Power BI or Tableau or digital dashboards. The emphasis now is on business systems like Customer Relationship Management (CRM), Supply Chain Management (SCM), or marketing systems, directly catering to business and sales needs.
In the retail industry scenario discussed in this article, the real-time data synchronization solution entails fetching data from Oracle databases representing point-of-sale (POS) systems across four regions (mainland China, Hong Kong, Macau, and Taiwan). This data is captured using LogMiner and undergoes various processing stages, including rule processing, script processing, field processing, case conversion, and more. The processed data is then written into MongoDB and subsequently transmitted to the search engine database in real-time.
MongoDB and the search engine database don’t necessarily follow a 1:1 relationship. TapData also applies some filtering to the models. This is because the primary data model in MongoDB is an all-encompassing wide table (including all product attributes for the entire group). The search engine database, on the other hand, is tailored to serve different front-end applications, resulting in diverse reports, including certain models delivered to the front end. The ultimate objective is to enable front-end users to rapidly access aggregated data without the need for manual group-by operations on the data, substantially enhancing query efficiency.
Throughout the data transfer process, TapData completes real-time incremental aggregation processing. The data that reaches the search engine database is exclusively data intended for front-end business presentation. It doesn’t follow the conventional development pattern where data is fetched from the database, and subsequently, either the front end or back end must process it before presentation.
Through this streaming processing approach, the source system’s data is processed and enriched in real-time and presented to the front end. For business and sales personnel, this facilitates direct access to the high-performance query database, significantly improving query efficiency.
In terms of incremental aggregation, two common scenarios are typically encountered. In the past, SQL was used, and a batch process was run overnight to complete the aggregation. In the contemporary landscape, many enterprises are resorting to Spark for this purpose, which effectively employs a windowing mechanism. Flink is increasingly adopted for real-time stream processing.
Our real-time aggregation framework conducts an initial full aggregation during the initialization phase. Subsequently, incremental aggregation is performed based on the group-by fields. Notably, a single source data record can correspond to several target data records. Even in cases of updates, inserts, deletions, or queries on the source, we can ensure that the relevant report figures are adjusted in real-time.
From a user’s perspective, a comprehensive data service platform is often desired. Users no longer wish to retrieve data from nine distinct Oracle databases and have their Java code carry out extensive calculations. What users seek is a unified gateway. For Database Administrators (DBAs), this is much easier to manage, as it only involves overseeing access and permissions for the unified gateway. Permissions for the application side are managed through a centralized data service. Application developers can access APIs as an entry point, allowing these APIs to seamlessly connect to our MongoDB and search engine database.

Once such a data service platform is established, it can be applied to various business centers, including the omnichannel product inventory center, marketing center, real-time inventory checks, and more. For users, integration costs are kept to a minimum because they only need to interact with APIs. These APIs adopt standard RESTful formats.
In this retail industry customer case, all databases are collected and synchronized into MongoDB for modeling. The modeling process may reference some data warehouse standards, but ultimately, it is tailored to suit business requirements.
After obtaining both master data and ODS (Operational Data Store) data, we can proceed to develop various business models.

In a scenario where we have a highly intricate product model and an order inventory model, generating daily sales reports for various stores is a breeze; all we need to do is aggregate the orders. Utilizing a real-time incremental aggregation framework, these reports can be rapidly computed. Now, let’s consider a situation where the business unit requires a monthly report. This report, too, is constructed through real-time aggregation. For models tailored for such queries, they consistently refer to a single inventory model. There may be occasions when the product model and inventory model are amalgamated, such as when we need to determine how many orders are associated with a specific product. This essentially involves the fusion of these two fundamental data models. Once we’ve established this intermediary layer of core data models, any business model built on top of it performs exceptionally well. The entire process is highly responsive, enabling application endpoints to access real-time data via APIs. Furthermore, these APIs are built upon databases like MongoDB, specifically designed for transaction processing (TP) businesses. Of course, TapData can handle AP as well, and it does so in real-time.
In summary, the journey of constructing a real-time data integration platform takes us from all sorts of Data Sources to MongoDB, delivering data through APIs to microservices. For front-end businesses, all group-level business systems are seamlessly integrated into this platform.

In our two-site dual-center architecture, one center is based in mainland China, and the other is located in Hong Kong. All our MongoDB instances are configured for distribution, and we employ a sharded cluster deployment for the search engine database to ensure high availability. Notably, we maintain a strict separation of read and write operations.
For instance, our primary node is situated in Hong Kong, making it the primary destination for data writes. However, when it comes to data reads, including those performed by our business clients, they access the nearest API endpoint. This read-write segregation, along with policy forwarding, is accomplished using a custom solution akin to the functionality provided by Apache.
To shed light on TapData’s implementation process, let me outline a few key steps. It all begins with a comprehensive understanding of the project requirements. Subsequently, we prepare the data sources, proceed with modeling across distinct layers, including the source layer, master data layer, and business layer, and ultimately take the system online. As for team roles, it’s worth noting that team members often wear multiple hats, but their core focus remains on data-related tasks.

This particular case doesn’t require an extensive server infrastructure. All the servers utilized are configured with either 8 cores and 16GB of RAM or 16 cores and 64GB of RAM, yet they efficiently manage data synchronization for the entire corporate group.

Our best practice is a three-tier modeling approach. To begin with, we store all the data in MongoDB, serving as the foundational data layer. Why do we choose this approach? Firstly, it significantly reduces the strain on the source databases, as they solely handle single-table synchronization without any additional computational load. Secondly, by storing the data within MongoDB, we avoid data redundancy. User data is stored here, eliminating the need to constantly fetch data from the source’s operational databases.

Moving forward, above the foundational data layer, we can swiftly establish a master data model, which in turn facilitates the creation of business and analytical models. Alternatively, you can build business models directly from the foundational data layer if a master data model isn’t necessary or if the existing master data model is overly complex. This represents our practical evolutionary process. As exemplified, the diagram illustrates an order model with associated order status flows. Previously, the entire order processing and its underlying logic were coded in Java and managed via message queues. Subsequently, these processes were integrated into our platform. The TapData Real-Time Data Services Platform extends beyond data synchronization at the foundational data layer, evolving into the modeling of data and the management of business relationships from the foundational data layer to the master data layer. This includes handling changes in order status and other vital attributes like price calculations and fluctuations in gold prices.

Following the implementation of an enterprise-level real-time data integration platform, clients have reaped several core benefits:
First and foremost, there’s a dramatic reduction in frontend response times, plummeting from 10 seconds to sub-second levels. The search engine database shoulders the entire burden of frontend operations, leading to a substantial boost in query performance, with the number of queries diminishing from five to just one.
The second advantage lies in significantly lowering data maintenance costs. Data portals have proven invaluable to DBAs, many of whom previously spent the majority of their workdays on data queries, including report generation. With the introduction of the real-time data integration platform, users can now engage in self-service operations on the platform. This extends to business analysts and non-technical personnel. As a result, DBAs have been freed from a substantial workload, and the development department no longer requires cross-departmental communication, thereby substantially improving development efficiency.

The third key benefit is an enhanced API process and shorter development cycles. In the past, the entire API development process could span two to three months, but now, it takes only a few days, and in no instance more than a week. This is primarily due to all data already residing in the platform. If data cannot be located temporarily on the platform, a simple synchronization is all that’s required to bring both data and models into the platform. The process, from submitting requirements to development and deployment, is remarkably swift. Additionally, when TapData releases APIs, Swagger auto-generates documentation, sparing developers the need to compose integration documentation manually.

Currently, over a dozen applications for this retail industry client are successfully operational on the TapData Real-Time Data Services Platform. Thanks to the integrated real-time data, a multitude of longstanding IT challenges have been successfully addressed. For those interested in delving deeper into the TapData Real-Time Data Services Platform, you are encouraged to explore our official website or request a trial of TapData products.
Author’s Bio:
Arthur Yang is a MongoDB Professionor (one of the top 15 MongoDB professionals in China), a featured guest lecturer for MongoDB at Ping An Group, and a certified CSDN blogger. With extensive experience in data platform architecture, he has led numerous projects related to real-time data integration platforms, spanning various industries, including retail, IoT, connected vehicles, education, and more.

